Artigos Técnicos
Análise de Subsistemas Avançados de Armazenamento
![]()
 “Quanto mais complexo o encanamento, mais fácil é entupir o ralo”
“Quanto mais complexo o encanamento, mais fácil é entupir o ralo”
Comandante Montgomery Scott - Star Trek II – A procura de Spock
Tipos de Conexão
Nesta área temos que considerar a conexão de duas áreas distintas. Uma é a que interliga os discos físicos às placas adaptadoras, conforme discutido no Capitulo 2 – Interfaces a disco. Uma outra é a que conecta as placas adaptadoras às estruturas de CACHE do subsistema. As implementações mais comuns são a de BARRAMENTO COMPARTILHADO (EMC Symmetrix 5.5 e anteriores), CONEXÃO DIRETA (EMC DMX e DMX3), BARRAMENTO PCI (IBM ESS), BARRAMENTO RIO (IBM DS), e CHAVEADO (HDS 9980V Lightning e USP).
Todas as arquiteturas atuais impõem a passagem de dados pelo CACHE, seja durante a leitura ou gravação. Portanto, um primeiro fator limitador de banda de backend é o número e a velocidade das conexões a ele. Por mais que o restante das ligações sejam rápidas, caso seu equipamento só disponha de 2 barramentos PCI para conexão ao CACHE, por exemplo, o máximo de taxa sustentável será de 133 MB/S (qualquer operação requer pelo menos dois acessos ao CACHE, uma entre o HA ou host adapter e o CACHE, e a outra entre ele e os discos, portanto, dos 2X133 disponíveis, somente a metade pode ser considerada – veja abaixo).
Em relação às arquiteturas de barramento, o ponto importante é que apenas uma operação pode ser conduzida de cada vez, pois todos funcionam com implementações de BUS MASTERING, o que exige arbitragem e serialização do recurso, restringindo o número máximo de operações SIMULTÂNEAS ao número total de barramentos disponíveis. No ambiente chaveado, o número de portas ao CACHE torna-se o fator limitante, uma vez que independentemente da quantidade de ligações que um SWITCH possa ter, uma dada área de CACHE somente poderá estar efetuando UMA transferência de dados de cada vez.
Em alguns casos (HDS e EMC), cada placa de CACHE dispõe de ASICs individuais para mais de uma região (4 para os exemplos acima), o que permite que 4 comunicações ocorram simultaneamente por placa. Se quiser saber o limite de operações simultâneas de seu backend (sustentáveis), basta multiplicar o número de regiões individuais de cada placa, pelo número disponível de placas de CACHE de seu equipamento.
Operações de HOST X Operações de BACKEND
O número de operações executadas pelo backend é, geralmente, diferente do número de operações enviadas pelo HOST, e deve ser considerado desta forma quando se dimensiona a capacidade necessária em um equipamento.
Tomando-se por exemplo uma operação de leitura, na qual os dados encontram-se no CACHE (READ HIT), os dados terão de fluir pelo equipamento apenas uma vez (em função da operação, uma vez que a leitura dos discos ao CACHE foi causada ou pelo algoritmo de pré-carga ou por uma outra operação). Neste caso, há uma correspondência 1X1 entre os dois. Entretanto, já um READ MISS fará com que :
1 - os dados sejam lidos do disco ao CACHE e
2 - do CACHE ao HOST ADAPTER.
Caso ambos os fluxos compartilhem dos mesmos caminhos (como no Symmetrix 5.5 e anteriores), a banda total da conexão tem de ser dividida por 2.
Uma operação de gravação, por sua vez, é influenciada por fatores como o esquema de proteção escolhido para o equipamento e o tamanho do bloco a ser gravado. No caso de RAID-0, como os dados são divididos entre um grupo de discos, haverá tantas operações de gravação quantas forem necessárias ao tamanho do bloco sendo gravado (p.ex. para um Blksize de 32K e um StripeSize de 8K serão necessários 4 acessos ao disco, mais a movimentação dos dados do HA ao CACHE, totalizando 5 acessos). Para um subsistema protegido por RAID-1, uma operação de gravação totaliza 3 movimentações de dados pelo subsistema. Uma do HA ao CACHE, e uma para cada cópia em disco.
Como regra geral, pode-se manter a relação 1X1 para CACHE HITS, 1X2 para operações CACHE MISS e gravações em RAID-1 e 1Xn para gravações em RAID-4 e 5 (sendo n o número de discos componentes do RAID-Group, e considerada a blocagem do acesso). Equipamentos em RAID-6 apresentam relações maiores, caso não seja utilizada qualquer forma de atenuação do mesmo (p.ex. o LOG STRUCTURED FILE do equipamento Sun/STK, que sempre grava blocos inteiros, evitando as penalidades de leitura de dados antigos e paridade). A nova implementação de PARITY RAID do EMC DMX e DMX3 utiliza circuitos nos próprios discos para gerar a paridade, resultando em um impacto 50% maior que o RAID-1 (3 operações comparadas com 2).
Operações em Placas Adaptadoras
Conforme visto na primeira unidade, cada disco físico é capaz de efetuar por volta de 150 operações por segundo em um ambiente típico de produção. Quantos então poderiam ser interligados a uma placa adaptadora, de forma que as limitações físicas desta última não implicassem em enfileiramentos aos mesmos ?
Experimentalmente, o número a ser usado vai de 1600 a 2200 operações por segundo, variando de acordo com o fabricante e modelo do equipamento considerado. Equipamentos de última geração tendem a suportar valores próximos ao maior limite desta faixa. Portanto, se considerarmos 130 iops nos discos físicos e uma maquina de tecnologia média (1800 iops, p.ex.), 14 discos físicos seriam o limite para esta placa.
Um ponto importante aqui é que há implementações nas quais uma mesma CPU de placa adaptadora é responsável por responder às operações de mais de um grupo de discos (por exemplo, dois barramentos SCSI em uma mesma CPU). Neste caso, o número a ser considerado é o total para a CPU da placa. No caso de nosso exemplo acima, 7 discos por barramento, no máximo. Há configurações que criam RAID-Groups entre discos de uma mesma placa (p.ex.: SSA groups no IBM ESS), enquanto outras definem os grupos entre discos de placas diferentes.
Um outro ponto a se considerar aqui é a distribuição de volumes lógicos. Novamente, dependente do fabricante, equipamento e configuração, pode-se distribuir os volumes lógicos seqüencialmente, dentro de um mesmo RAID-Group, ou criá-los entre grupos diferentes. Por exemplo, o endereço 3000 pertence ao RG0 enquanto o 3001 já é definido no RG1. De um modo geral, a dispersão externa (entre discos de RGs diferentes), facilita, inicialmente, a dispersão de volumes lógicos, sendo por isso a preferida de iniciantes. Entretanto, pouco tempo depois, descobre-se que uma tal configuração apresenta enormes dificuldades de gerência e dispersão manual. Outros conceitos como o de METAGROUPs, que é a união de mais de 1 RAID-Group para formar um único RG lógico, sobre o qual os volumes serão distribuídos, acrescenta ainda mais complexidade ao ambiente.
Melhorias de backend
Há duas formas básicas de se obter melhorias de backend. Uma é acelerando suas operações (barramentos ou discos mais velozes, por exemplo), e a outra é desengargalando estas operações (mais barramentos ou mais discos, seguindo a linha do exemplo anterior). Mesmo sem a aquisição de novos equipamentos ou componentes, ainda é possível melhorar o desempenho de um subsistema, utilizando-se técnicas tão antigas quanto a dispersão dos volumes mais acessados.
Ainda hoje a regra 80/20 se mantém (80% das operações são feitas contra 20% dos volumes), o que permite que as unidades com maior concentração de carga sejam espalhadas pelo sistema mais facilmente. Caso as opções de proteção tendam a concentrar o acesso de volumes lógicos em poucos físicos, um SORT decrescente pela coluna DEVICE ACTIVITY RATE do RMF-I PP DASD REPORT basta para isso. Tal dispersão, abrangendo também unidades de controle, canais e partições distintas, otimiza o acesso e evita o enfileiramento de operações por falta de recursos. É importante ter em mente que assim como qualquer equipamento pode ser “afinado” para o melhor desempenho de sua arquitetura, também pode ser exposto a um cenário no qual apresentará problemas. Não há uma única solução “certa” ou “melhor” para todo e qualquer ambiente.
Todo e qualquer subsistema pode apresentar atrasos de backend. Braços mecânicos se movendo, setores de disco girando para a posição desejada, barramentos SCSI ou links FC-AL ocupados, placas de CACHE com todas as regiões já atendendo outras operações são apenas alguns dos exemplos do que pode causar isso. Quanto mais baixa for a taxa de CACHE-HIT do ambiente, mais grave o problema tende a se tornar. E com tantas implementações distintas, utilizando diferentes tecnologias, como avaliar o desempenho ? A resposta é simples : use sempre a mesma moeda !
Conforme descrito no Capitulo I – Discos Físicos, uma operação de I/O a um destes dispositivos pode levar tempos em torno de 15 mS (9,70 Full Stroke Seek + 5,98 Max.Latency). Concedendo-se acréscimos devido a atrasos de protocolo, repetição de operações por formatação, etc, é razoável utilizar-se, como unidade padrão de medida algo em torno de 22mS (quase 38% de acréscimo sobre os tempos mecânicos). De fato, tempos por volta de 25mS são os mais comumente medidos para operações a disco em grandes subsistemas. Pode-se optar por um ou outro, mantendo-se em mente que este valor aplica-se à controladoras utilizando os discos de exemplo do primeiro capitulo. Outros dispositivos, com tempos diferentes, devem ter este valor recalculado. Para efeitos deste trabalho, vou me referir a este tempo como DISK IOTIME.
Portanto, assumindo-se que 22mS seja o DISK IOTIME apropriado para o subsistema em análise, uma outra informação à ser obtida é o REAL DISCONNECT TIME para o ambiente.
Da forma como é reportado pelo RMF, há uma certa tendência a se interpretar de forma incorreta o tempo de DISC de uma unidade ou controladora. Veja o exemplo abaixo :
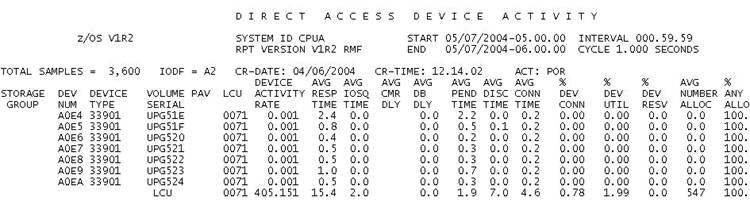
Figura 18 – DASD REPORT
A LCU 0071 apresenta para este período (05:00:00 – 06:00:00 do dia 07/05/2004) e esta partição (CPUA) um tempo médio de DISC de 7.0 mS, para uma taxa de operações de mais de 405 iops. Entretanto, este NÃO É o tempo REAL de DISC destas operações, por uma razão muito simples. As operações CACHE-HIT não têm DISC, e deveriam ser descontadas deste valor. Veja a figura a seguir
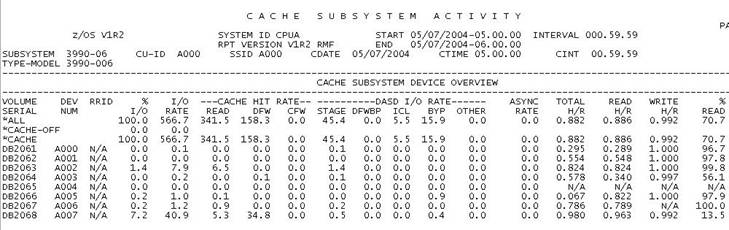
Figura 19 - CACHE Report
Esta mesma controladora (para o range A000 – A0FF), no CACHE REPORT é identificada pelo seu CU-ID A000 (endereço do primeiro dispositivo a ser acessado durante a ativação do subsistema), apresenta um CACHE-HIT RATIO de 88.2%, o que significa que das 405 operações por segundo, somente 11,4% ou 46.2 iops sofreram qualquer atraso por DISC. Portanto, para determinação do REAL DISC, deve-se desconsiderar as outras operações na hora de dividir o tempo acumulado, conforme os passos descritos a seguir (para o RMF de exemplo)
Portanto, o que o RMF indica como um DISC TME médio de 7.0 mS na verdade foi causado pela distribuição dos 61.4 mS de DISC que cada uma das 46 operações CACHE-MISS sofreu, entre as 405 operações efetuadas no período.
É importante lembrar que as controladoras reportam informações de CACHE para a IMAGEM COMO UM TODO, sendo incorreta a extração deste relatório por todas as partições de um ambiente data-share. Como o próprio manual do RMF informa, ele deve ser tirado por APENAS UMA das partições que tem acesso ao subsistema. No exemplo acima, assumimos que apenas a partição CPUA tinha acesso ao subsistema, e, portanto, seus dados são válidos para comparação com o DASD REPORT.
Agora, de posse destes dois valores, DISK IOTIME (para nosso exemplo, 22mS), e o REAL DISC TME (61,4mS), podemos definir um consenso de medida que chamo de BACKEND QUEUING. Ou seja, enfileiramento de backend.
Semelhante ao IOSQ que determina quantas operações ficam, na media, aguardando enfileirados na UCB aguardando seu SSCH, o BK-Q determina, em média, quantas operações ficam aguardando execução. Para determiná-lo, basta dividir-se o REAL DISC TME pelo DISK IOTIME. No nosso caso (61,4 / 22) temos 2,792109, ou 2.8 IOs na fila do backend, em média, para aquele período.
Este valor, por tratar exclusivamente de cargas CACHE-MISS é bem mais apropriado à avaliação de placas adaptadoras, discos e barramentos, que, por exemplo, o RT médio. A sugestão aqui é que o BK-Q fosse calculado para cada subsistema presente no ambiente, e para cada período (BATCH, ONLINE, FECHAMENTO, etc), de forma a se ter uma referencia para casos da performance piorar. Se o RT aumenta, por exemplo, foi a CARGA TOTAL que aumentou, o CACHE HIT que baixou, ou o BKND da máquina que atingiu seu ponto de saturação ? Para tal controle, pode-se plotar uma curva comparando IORATE por BK-Q, por exemplo, e fica-se sabendo de antemão quando o cotovelo é atingido. Uma curva 3D seria ideal, comparando IORATE, CACHE-HIT e BK-Q.
Mais que isso, o BK-Q serve também para se comparar resultados entre arquiteturas completamente distintas. Se um fornecedor possui BKND FC-AL com discos de 45Krpm e o outro somente SCSI com 7.2 ATA drives, mas os dois lhe dão o mesmo nível de BK-Q para uma mesma carga (e o mesmo cache-hit, é claro), do ponto de vista de desempenho, o ATA substituiria o outro tranqüilamente, e geralmente com significativos ganhos financeiros !
Uma outra utilidade é avaliar as especificações de um novo produto. Caso o fornecedor garanta que seu novo equipamento é, digamos, duas vezes melhor que o anterior ou o competidor, o BK-Q pode fazer parte dos números apurados para averiguação destas afirmações. Uma fila da metade do tamanho (1/2 BK-Q) significa um backend 2 vezes melhor.
![]()
![]()
![]()
![]()